Class Prevalence Estimation with freq-e
Problem
For a collection of items, such as documents or images, how can we infer the proportion of items in a category? This problem is known as prevalence estimation (in statistics and epidemiology), quantification (in data mining), and class prior estimation (in machine learning). For example, one may want to use a small sample of documents and sentiment labels ((x,y) pairs) to train a text sentiment model, then infer the amount of positive discussion over time in new, unlabeled texts (just x's).
In our academic paper, Uncertainty-aware generative models for inferring document class prevalence (Keith and O'Connor 2018), we show that naive approaches, which aggregate the hard labels or soft probabilities outputted from a trained discriminative classifier, are often biased. Instead, we propose an implicit likelihood method that directly conducts inference for the class prior distribution, combining a conventional discriminitive classifier with a generative modeling framework. Its main advantages include
- More robust accuracy when the true prevalences of the train and test groups differ, as is the case for many important analysis problems (for example, finding category variability over time, or across groups); and,
- The ability to infer confidence intervals describing the model's uncertainty about the true value of the class prevalence.
freq-e software for class prevalence estimation
We have developed a software package that employs our implicit likelihood method called freq-e. See the freq-e github repository for a more detailed tutorial.
You can install the software via pip install freq-e (using Python 3).
Paper replication code
The code to replicate experiments in the academic paper is available [here].
Results highlights
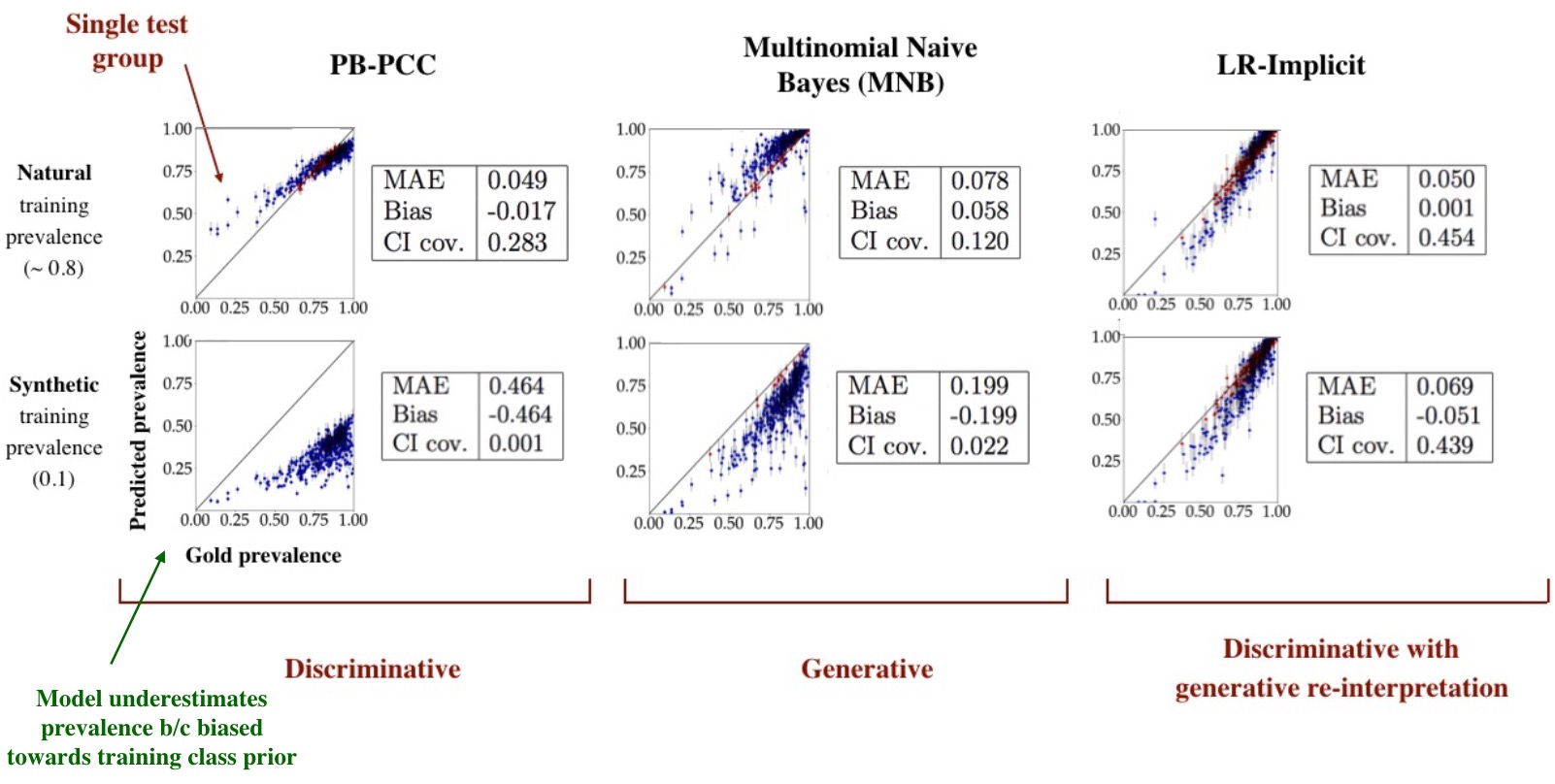
This diagram shows empirical results for predicting class prevalences across several hundred test sets. The three columns represent different text and class inference models, while the rows indicate whether the labeled traning data matches the test sets' class distributions. PB-PCC refers to the naive method of summing together a logistic regression's predictions; it is heavily biased toward the training data. MNB, a classic generative model of labeled text, is more robust to this type of bias, but its overall class accuracy is worse. Our implicit likelihood model combines both of these advantages, with similar or better point estimation error (MAE) and less bias. Confidence interval coverage is better, though more work is required to achieve the nominal coverage rate. See the paper for more details.
BibTex
@inproceedings{keith18uncertainty,
author = {Keith, Katherine A. and O'Connor, Brendan},
title = {Uncertainty-aware generative models for inferring document class prevalence},
booktitle = {Proceedings of {EMNLP}},
year = 2018}